基于分数的生成模型
(Score-based generative models)
原文链接:
通过前面的学习,我们发现扩散模型可以从不同的角度进行解释。 其中一个等价的解释是基于分数的生成模型,前面章节虽然简单介绍了下, 但没有详细说明,本章我们详细讨论下基于分数的生成模型。 基于分数的生成模型是由宋旸等人在2019年提出 [1] 的, 后来他们又提出了基于随机微分方程的更一般的形式 [2] , 本章我们一起讨论学习一下。
Scored-based的生成模型
在前面 DDPM 和 DDIM 的章节中,已经探讨了 DDPM 的降噪过程,可以看做是沿着分数(梯度)∇ l o g p ( x t ) ∇logp(x_t) ∇ l o g p ( x t ) 基于分数 (Score-based)的论文 相关工作并不是建立在 DDPM 的基础上,所以论文里不是从DDPM的马尔科夫链式结构讨论和导出的,而是直接从分数匹配估计算法推导。
首先看下基于分数的生成模型的核心思想。假设我们有一些服从某个分布的观察数据 ,比如大量的图片数据, 但是这些数据背后真实的概率分布是未知 的, 我们暂且用符号 p d a t a ( x ) p_{data}(x) p d a t a ( x )
我们希望能生成新的数据 ,也就是想从分布p d a t a ( x ) p_{data}(x) p d a t a ( x ) 采样新的样本 ,比如采样生成新的图片。
但分布p d a t a ( x ) p_{data}(x) p d a t a ( x ) p d a t a ( x ) p_{data}(x) p d a t a ( x ) 它的分数 $$∇_xlog(p_{data}(x))$$(基于数据变量x x x p d a t a ( x ) p_{data}(x) p d a t a ( x )
为什么对l o g ( p d a t a ( x ) ) log(p_data(x)) l o g ( p d a t a ( x ) )
使用对数概率 log(p(x)) 而非直接使用 p(x) 有几个原因。首先,对数转换可以帮助稳定数值计算,因为概率值 p(x) 可能非常小,直接处理这些小数可能导致数值不稳定。其次,对数转换增加了梯度的灵敏度,对于低概率区域,即使是微小的概率变化,也会在对数尺度上产生较大的变化 ,从而使模型能够更敏感地捕捉到数据分布的细微特征。
自然梯度与分数匹配 :在统计学习和信息理论中,自然梯度(即概率分布的梯度)被用于描述信息几何中的最优化问题。分数匹配算法就是利用了这一点,通过匹配数据分布的梯度来学习和近似真实分布。这种方法直接对接到了概率分布的本质特征上,使得模型能够更加精确地捕捉和生成数据。简化学习问题 :当我们使用 log(p(x)) 的梯度时,学习问题简化为学习这个梯度的近似表示。这通常比直接学习复杂的数据分布 p(x) 更容易,因为梯度信息提供了关于如何调整参数以更好地逼近数据分布的直接指导。
这样基于分数的采样方法 有很多,可以从中选择一个合适的采样方法。 所以基于分数的生成模型,宏观来看就两步:
利用分数匹配方法估计 出数据分布 p d a t a ( x ) p_{data}(x) p d a t a ( x ) 近似分数 s θ ( x ) ≈ ∇ x log p data ( x ) s_{\theta}(x) \approx \nabla_{x} \log p_{\text{data}}(x) s θ ( x ) ≈ ∇ x log p data ( x )
使用这个基于近似分数 s θ ( x ) s_{\theta}(x) s θ ( x ) p data ( x ) p_{\text{data}}(x) p data ( x )
分数匹配算法(Score Matching)
分数匹配(Score Matching),简单来说它就是一种概率密度估计的方法。 该方法在多元高斯和独立分量分析模型上得到了证明 3 。 在概率统计学中,很多概率密度函数可以写成如下的形式,比如无向图中的概率密度,通过贝叶斯公式推导出的后验概率分布等等。
公式1.1
p ( x ; θ ) = q ( x ; θ ) Z p(x;\theta) = \frac{q(x;\theta)}{Z}
p ( x ; θ ) = Z q ( x ; θ )
其中
θ \theta θ x x x Z Z Z q ( x ; θ ) / Z q(x;\theta)/Z q ( x ; θ ) / Z 1 1 1 Z Z Z
公式1.2
Z = ∫ q ( x ; θ ) d x Z = \int q(x;\theta) dx
Z = ∫ q ( x ; θ ) d x
然而很多情况下Z Z Z 无法得到概率密度 p ( x ; θ ) p(x;\theta) p ( x ; θ ) 用最大似然估计 能帮我们估计出未知参数 θ \theta θ p ( x ; θ ) p(x;\theta) p ( x ; θ ) p ( x ; θ ) p(x;\theta) p ( x ; θ )
而分数匹配 就是帮我们估计 出 p ( x ; θ ) p(x;\theta) p ( x ; θ ) 近似表示 ,我们用这个近似表示来代替原本的 p ( x ; θ ) p(x;\theta) p ( x ; θ )
假设我们有变量 x x x p data ( x ) p_{\text{data}}(x) p data ( x ) 数据的真实分布 ,然后定义一个近似的参数化分布(训练的模型)表示为 p θ ( x ) p_{\theta}(x) p θ ( x )
公式1.3
J ( θ ) = 1 2 ∫ p data ( x ) ∥ ∇ log p data ( x ) − ∇ log p θ ( x ) ∥ 2 d x = 1 2 E [ p data ( x ) ] ∥ ∇ log p data ( x ) − ∇ log p θ ( x ) ∥ 2 J(\theta) \\= \frac{1}{2} \int p_{\text{data}}(x) \left\lVert \nabla \log p_{\text{data}}(x) - \nabla \log p_{\theta}(x) \right\rVert^2 d x
\\=\frac{1}{2} \mathbb{E}[p_{\text{data}}(x)]{ \left\lVert \nabla \log p_{\text{data}}(x) - \nabla \log p_{\theta}(x) \right\rVert^2 }
J ( θ ) = 2 1 ∫ p data ( x ) ∥ ∇ log p data ( x ) − ∇ log p θ ( x ) ∥ 2 d x = 2 1 E [ p data ( x ) ] ∥ ∇ log p data ( x ) − ∇ log p θ ( x ) ∥ 2
为了符号简洁,分别定义 s θ ( x ) = ∇ log p θ ( x ) s_{\theta}(x)=\nabla \log p_{\theta}(x) s θ ( x ) = ∇ log p θ ( x ) s d a t a ( x ) = ∇ log p data ( x ) s_{data}(x)=\nabla \log p_{\text{data}}(x) s d a t a ( x ) = ∇ log p data ( x ) x x x θ \theta θ
公式1.4
J ( θ ) = 1 2 ∫ p data ( x ) ∥ s d a t a ( x ) − s θ ( x ) ∥ 2 2 d x = 1 2 E [ p data ( x ) ] ∥ s d a t a ( x ) − s θ ( x ) ∥ 2 2 J(\theta) \\= \frac{1}{2} \int p_{\text{data}}(x) \left\lVert s_{data}(x) - s_{\theta}(x) \right\rVert^2_2 d x
\\= \frac{1}{2} \mathbb{E}[p_{\text{data}}(x)]{ \left\lVert s_{data}(x) - s_{\theta}(x) \right\rVert^2_2 }
J ( θ ) = 2 1 ∫ p data ( x ) ∥ s d a t a ( x ) − s θ ( x ) ∥ 2 2 d x = 2 1 E [ p data ( x ) ] ∥ s d a t a ( x ) − s θ ( x ) ∥ 2 2
通过极小化目标函数 求得参数化分布的未知参数θ \theta θ
θ ^ = arg min θ J ( θ ) \hat{\theta} = \operatorname*{\arg \min}_{\theta} \ J(\theta)
θ ^ = θ arg min J ( θ )
单纯的看这个目标函数似乎很简单,他就是一个均方误差而已,它的目标是令近似分布的对数概率密度梯度和真实数据分布的对数概率密度的梯度尽量相近 ,这其实建立在:如果两个分布的对数密度梯度是一样的,那么他们的概率密度也是一样的。这个目标函数形式很简单,但是有个问题,就是 s d a t a ( x ) s_{data}(x) s d a t a ( x )
得到了目标函数的一个等价表示
公式1.5
J ( θ ) = ∫ p data ( x ) [ t r ( ∇ x s θ ( x ) ) + 1 2 ∥ s θ ( x ) ∥ 2 2 ] d x = E [ p data ( x ) ] t r ( ∇ x s θ ( x ) ) + 1 2 ∥ s θ ( x ) ∥ 2 2 J(\theta) \\= \int p_{\text{data}}(x) \left [ tr( \nabla_{x} s_{\theta}(x))
+ \frac{1}{2} \left\lVert s_{\theta}(x) \right\rVert^2_2 \right ] d x
\\= \mathbb{E}[p_{\text{data}}(x)] { tr( \nabla_{x} s_{\theta}(x))
+ \frac{1}{2} \left\lVert s_{\theta}(x) \right\rVert^2_2 }
J ( θ ) = ∫ p data ( x ) [ t r ( ∇ x s θ ( x ) ) + 2 1 ∥ s θ ( x ) ∥ 2 2 ] d x = E [ p data ( x ) ] t r ( ∇ x s θ ( x ) ) + 2 1 ∥ s θ ( x ) ∥ 2 2
其中 ∇ x s θ ( x ) \nabla_{x} s_{\theta}(x) ∇ x s θ ( x ) s θ ( x ) s_{\theta}(x) s θ ( x ) log p θ ( x ) \log p_{\theta}(x) log p θ ( x ) t r ( ⋅ ) tr(\cdot) t r ( ⋅ ) s θ ( x ) s_{\theta}(x) s θ ( x )
从公式1.4 到公式1.5 的推导过程这里不再赘述,详细过程可以参考论文 EstimationofNon-NormalizedStatisticalModels byScoreMatching 。
然而事情还没有完,二阶偏导 t r ( ∇ x s θ ( x ) ) tr( \nabla_{x} s_{\theta}(x)) t r ( ∇ x s θ ( x ) ) x x x
分层分数匹配(Sliced score matching)
分层分数匹配使用一个随机投影矩阵可以 近似 计算 t r ( ∇ x s θ ( x ) ) tr( \nabla_{x} s_{\theta}(x)) t r ( ∇ x s θ ( x ) )
公式1.6
E p v E [ p data ( x ) ] v T ∇ x s θ ( x ) v + 1 2 ∥ s θ ( x ) ∥ 2 2 \mathbb{E}_{p_v} \mathbb{E}[p_{\text{data}}(x)] { v^T \nabla_{x} s_{\theta}(x) v
+ \frac{1}{2} \left\lVert s_{\theta}(x) \right\rVert^2_2 }
E p v E [ p data ( x ) ] v T ∇ x s θ ( x ) v + 2 1 ∥ s θ ( x ) ∥ 2 2
其中 p v p_v p v v T ∇ x s θ ( x ) v v^T \nabla_{x} s_{\theta}(x) v v T ∇ x s θ ( x ) v
降噪分数匹配(Denoising score matching)
另一种解决分数匹配的方法是降噪分数匹配 (Denoising score matching),它是分数匹配算法的一个变种,它可以完全避开 t r ( ∇ x s θ ( x ) ) tr( \nabla_{x} s_{\theta}(x)) t r ( ∇ x s θ ( x ) ) x x x 添加一些预先设定好的噪声数据 ,得到了新的数据 x ~ \tilde{x} x ~ 相当于构建了一条件概率分布 q σ ( x ~ ∣ x ) q_{\sigma}(\tilde{x}|x) q σ ( x ~ ∣ x ) q σ ( x ~ ) q_{\sigma}(\tilde{x}) q σ ( x ~ )
公式1.7
q σ ( x ~ ) ≜ ∫ q σ ( x ~ ∣ x ) p data ( x ) d x q_{\sigma}(\tilde{x}) \triangleq \int q_{\sigma}(\tilde{x}|x) p_{\text{data}}(x) d x
q σ ( x ~ ) ≜ ∫ q σ ( x ~ ∣ x ) p data ( x ) d x
然后把分数匹配算法应用在这个加噪后的数据分布上,
公式1.8
1 2 E q σ ( x ~ ∣ x ) [ ∥ s θ ( x ~ ) − ∇ x ~ log q σ ( x ~ ) ∥ 2 2 ] = 1 2 E q σ ( x ~ ∣ x ) p data ( x ) [ ∥ s θ ( x ~ ) − ∇ x ~ log q σ ( x ~ ∣ x ) ∥ 2 2 ] \frac{1}{2} \mathbb{E}_{q_{\sigma}(\tilde{x}|x) }
\left [ \left\lVert s_{\theta}(\tilde{x}) -\nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}) \right\rVert^2_2 \right ]
\\= \frac{1}{2} \mathbb{E}_{q_{\sigma}(\tilde{x}|x) p_{\text{data}}(x) }
\left [ \left\lVert s_{\theta}(\tilde{x}) -\nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}|x) \right\rVert^2_2 \right ]
2 1 E q σ ( x ~ ∣ x ) [ ∥ s θ ( x ~ ) − ∇ x ~ log q σ ( x ~ ) ∥ 2 2 ] = 2 1 E q σ ( x ~ ∣ x ) p data ( x ) [ ∥ s θ ( x ~ ) − ∇ x ~ log q σ ( x ~ ∣ x ) ∥ 2 2 ]
这么做的一个前提是,如果添加的噪声足够小 ,那么 q σ ( x ~ ) ≈ p data ( x ) q_{\sigma}(\tilde{x}) \approx p_{\text{data}}(x) q σ ( x ~ ) ≈ p data ( x ) ∇ x ~ log q σ ( x ~ ) ≈ ∇ x log p data ( x ) \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}) \approx \nabla_{x} \log p_{\text{data}}(x) ∇ x ~ log q σ ( x ~ ) ≈ ∇ x log p data ( x ) 分数匹配算法 估计出 q σ ( x ~ ) q_{\sigma}(\tilde{x}) q σ ( x ~ ) ∇ x ~ log q σ ( x ~ ) \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}) ∇ x ~ log q σ ( x ~ ) p data ( x ) p_{\text{data}}(x) p data ( x )
从中,我们知道了Diffusion核心思想
原样本x x x p d a t a ( x ) p_{data}(x) p d a t a ( x ) 我们要知道它 (从而生成新样本)
于是,给样本x x x 预定的噪声 (噪声很小),从而得到一堆新样本x ~ \tilde x x ~ x ~ \tilde x x ~ q σ ( x ~ ∣ x ) q_{\sigma}(\tilde{x}|x) q σ ( x ~ ∣ x ) 边缘化计算方法 (对x x x q σ ( x ~ ) q_{\sigma}(\tilde{x}) q σ ( x ~ )
如果噪声很小,我们可以认为 q σ ( x ~ ) ≈ p data ( x ) q_{\sigma}(\tilde{x}) \approx p_{\text{data}}(x) q σ ( x ~ ) ≈ p data ( x ) x x x
网络逐渐学会如何从给定的噪声分布中生成样本 ,同时也学会了如何去除这些噪声以还原出原始样本。这意味着网络在逐渐学习并逼近了p d a t a ( x ) p_{data}(x) p d a t a ( x ) q σ ( x ~ ) q_{\sigma}(\tilde{x}) q σ ( x ~ )
基于分数的生成模型面临的困难
理想是美好的,现实是残酷的。虽然我们想到了这种基于分数的采样模型,然而在实际应用时需要面临一些困难,论文中主要提出了两类困难:
分数匹配算法估计分数的准确性问题。
基于分数的采样算法的准确性问题。
分数估计不准的问题
论文中一共提出两个原因会导致分数估计不准确,一个是流体假设问题,一个是低密度区域样本不足的问题。
流形假设问题
首先看流体假设问题,论文指出了流形假设的存在,即现实世界中的数据往往集中在嵌入高维空间的低维流形 上。x x x n n n n n n 含有信息的真正维度往往小于 n n n
比如一张 4096 × 2160 4096 \times 2160 4 0 9 6 × 2 1 6 0 4096 × 2160 = 8847360 4096 \times 2160=8847360 4 0 9 6 × 2 1 6 0 = 8 8 4 7 3 6 0 880 w 880w 8 8 0 w 1920 × 1080 = 1080 P 1920 \times 1080=1080P 1 9 2 0 × 1 0 8 0 = 1 0 8 0 P 图像的关键信息可能并没有丢失 。也就是说原来 4K 图像中很多像素点其实可有可无 ,并没有包含有意义的信息。
这里我换个容易理解的说法,从小学数学说起。在学线性方程组时,我们知道方程组的解有无解、唯一解、无穷解等等情况。假设有一个包含 n n n m m m m m m m m m
但是你的方程与方程之间,系数与系数之间可能存在着线性相关 ,即某个方程可以通过其它方程线性变化得到,某个系数可以通过其它系数线性变换得到,这样的方程称为无效方程 ,这样的系数对应的参数称为无效参数或者自由参数。
假设方程组中有意义的方程为 n ~ \tilde{n} n ~ n ~ \tilde{n} n ~ m ~ \tilde{m} m ~
当 $ \tilde{n}<\tilde{m}$ 时,意为着有意义方程数量不足以确定全部参数的值,此时就方程组会有无穷解 。有意义的观测样本 (方程)数量少于观测变量 (系数)的数量。
当 $ \tilde{n}<n$ 时,此时意为着有部分系数之间不是相互独立的,这些系数对应的参数就成了自由参数,它的值可以是任意的,此时就方程组也会有无穷解 。这种情况,就相当于在机器学习场景中,你的特征变量 (观测变量)不是相互独立的,存在线性相关 。
进入到线性代数,线性方程组可以用形如 A θ = b A\theta=b A θ = b A A A θ \theta θ b b b
矩阵 A A A θ \theta θ
如果矩阵 $A $ 列满秩,意味着观测变量(系数)之间是相互独立的,每一个观测变量都含有有意义的信息;反之,如果观测变量(系数)之间是部分存在线性关系(或者一一映射),则矩阵 A A A A A A
回到流形假设问题,流行假设描述的是 类似列不满秩的情况 ,就是说我们观测到的数据维度是 m m m m m m
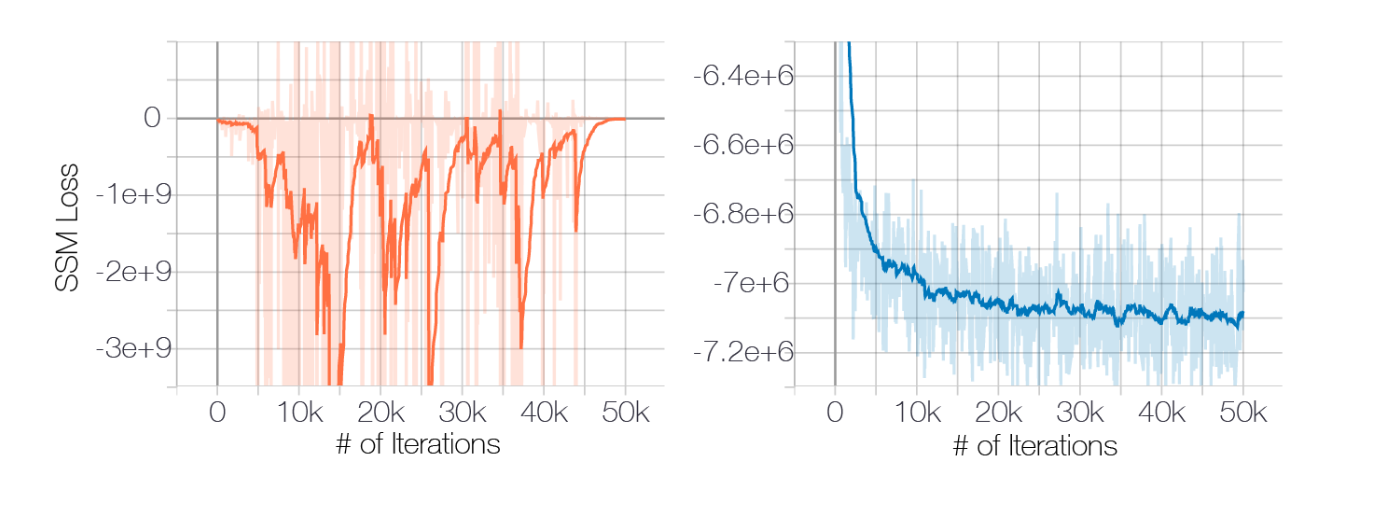
反映到分数估计算法上,这些变量的分数(偏导数)理论上有任意解,不稳定,呈现出来的现象就是训练时 Loss 不稳定不收敛,会反复横跳 ,具体可以看原论文里的实验和图解。
低密度的问题
另一个影响分数估计准确性的是概率密度的低密度问题 ,这个问题其实很简单, 本质上就是观测样本不足的问题 。 我们知道,对于一个非均匀分布的概率分布来说,其概率密度是不均匀的,概率密度低的地方意为着产生概率低, 那理论上获得这些区域的观测样本的概率就小。也就说,大多数情况下,对于低概率密度的区域, 我们观测样本覆盖是不足的 ,这时自然分数估计算法这些区域的拟合和学习就不足, 显然它对这些区域的预测也将不准。
郎之万动力采样不准的问题
郎之万动力采样(Langevin dynamics sample)算法,是一种利用分数从目标概率分布采样的方法,假设目标概率分布 是 p ( x ) p(x) p ( x ) 分数表示 为 ∇ x log p ( x ) \nabla_{x} \log p(x) ∇ x log p ( x ) 固定的步进 ϵ > 0 \epsilon >0 ϵ > 0 x ~ ∼ π ( x ) \tilde{x} \sim \pi(x) x ~ ∼ π ( x ) π ( x ) \pi(x) π ( x ) 先验分布 ,
郎之万动力采样通过如下迭代方程得到一个目标分布 p ( x ) p(x) p ( x )
公式1.9
x ~ t = x ~ t − 1 + ϵ 2 ∇ x log p ( x ~ t − 1 ) + ϵ z t , z t ∼ N ( 0 , I ) \tilde{x}_{t} = \tilde{x}_{t-1} + \frac{\epsilon}{2} \nabla_{x} \log p( \tilde{x}_{t-1}) + \sqrt{\epsilon} z_t
, \quad
z_t \sim N(\mathcal{0,\textit{I}})
x ~ t = x ~ t − 1 + 2 ϵ ∇ x log p ( x ~ t − 1 ) + ϵ z t , z t ∼ N ( 0 , I )
当满足 ϵ → 0 \epsilon \rightarrow 0 ϵ → 0 T → ∞ T \rightarrow \infty T → ∞ x ~ T \tilde{x}_{T} x ~ T p ( x ) p(x) p ( x ) x ~ T \tilde{x}_{T} x ~ T p ( x ) p(x) p ( x )
当然如果 ϵ > 0 \epsilon > 0 ϵ > 0 T < ∞ T < \infty T < ∞ ϵ \epsilon ϵ T T T
郎之万动力采样的优势 就是它只需要有目标分布的分数就行了,不需要知道目标分布 p ( x ) p(x) p ( x )
仔细观察下这个公式,这不就是一个梯度迭代法 么,让 x t x_t x t p ( x ) p(x) p ( x ) p ( x ) p(x) p ( x ) 概率密度最大 的点前进,迭代过程中加入一个随机高斯噪声 z t z_t z t
既然就是个梯度迭代,那我加入二阶梯度是不是采样能更快点?
然而郎之万动力采样存在一个显著的缺陷 ,当数据分布是一个很复杂的分布 时,比如存在低密度区域 ,并且低密度区域把整个概率密度空间分割成多个区域时,郎之万动力采样法无法在合理的时间能得到正确的采样,最典型的例子就是高斯混合分布 ,原论文就是用两个分量的混合高斯分布做实验和举例,论证了在这种情况下郎之万动力采样法无法健康工作。
当然如果T T T T T T
通过加噪的方法估计分布的近似分数
通过上一节,我们知道了基于分数的生成模型,面临两个困难,
高维空间有效性问题,有意义信息的维度可能远远小于观测数据的维度,导致分数估计算法不收敛。
数据分布低密度区域问题,低密度区域一方面因为样本不足令分数匹配算法估计不准,另一方面使郎之万采样算法无法在可接受的步数内得到有效采样。
那怎么解决呢?你猜对了,通过对数据添加高斯噪声解决 。
为什么添加噪声能解决上述问题呢?思考下,原数据分数是 p d a t a ( x ) p_{data}(x) p d a t a ( x ) 对应条件概率分布 q σ ( x ~ ∣ x ) q_\sigma(\tilde{x}|x) q σ ( x ~ ∣ x ) x ~ \tilde{x} x ~ q σ ( x ~ ) = ∫ q σ ( x ~ ∣ x ) p d a t a ( x ) d x q_\sigma(\tilde{x}) = \int q_\sigma(\tilde{x}|x) p_{data}(x) dx q σ ( x ~ ) = ∫ q σ ( x ~ ∣ x ) p d a t a ( x ) d x
添加噪声 就相当于改变了原来的数据分布 ,这种改变影响两个方面:
会破坏掉原来数据变量 x x x 相关性 ,使得各个维度(分量)间相关性减弱 ,相当于 x x x 满秩 了。
会改变 p d a t a ( x ) p_{data}(x) p d a t a ( x ) 分量之间添加的噪声是同等权重 的,低密度区域会密度变高 ,相对来说整个密度空间变得均匀了。
添加的噪声越多,对上述两点的影响越大,对问题的改善就越好。这种加噪声的方法又完美契合了上面介绍的分数匹配两种方法之一的降噪分数匹配,就是这么的巧合。
但是,但是,这里有冲突!!!
回看一下降噪分数匹配算法,它成立的条件是添加的噪声不能太多 啊,不然 q σ ( x ~ ) q_\sigma(\tilde{x}) q σ ( x ~ ) p d a t a ( x ) p_{data}(x) p d a t a ( x ) q σ ( x ~ ) q_\sigma(\tilde{x}) q σ ( x ~ ) p d a t a ( x ) p_{data}(x) p d a t a ( x )
但又需要足够的大噪声 去改善上述两个问题,噪声不够大,这两个问题解决不彻底啊!!!
那么怎么解决?既然有的人贪心要的多,有的人佛系要的少,重口难调。
那么就按需分配,设置不同强度等级噪声 ,各种强度等级的噪声都安排上
令 { σ i } i = 1 L \{\sigma_i\}_{i=1}^L { σ i } i = 1 L σ 1 σ 2 = ⋯ = σ L − 1 σ L \frac{\sigma_1}{\sigma_2}=\cdots=\frac{\sigma_{L-1}}{\sigma_{L}} σ 2 σ 1 = ⋯ = σ L σ L − 1
令条件分布 q σ i ( x ~ ∣ x ) q_{\sigma_i}(\tilde{x}|x) q σ i ( x ~ ∣ x )
公式1.10
q σ i ( x ~ ∣ x ) ∼ N ( x ~ ∣ x , σ i 2 I ) q_{\sigma_i}(\tilde{x}|x) \sim \mathcal{N}( \tilde{x}|x, \sigma_i^2 \textit{I} )
q σ i ( x ~ ∣ x ) ∼ N ( x ~ ∣ x , σ i 2 I )
令q σ i ( x ~ ) q_{\sigma_i}(\tilde{x}) q σ i ( x ~ )
公式1.11
q σ i ( x ~ ) ≜ ∫ p d a t a ( x ) q σ i ( x ~ ∣ x ) d t q_{\sigma_i}(\tilde{x}) \triangleq
\int p_{data}(x) q_{\sigma_i}(\tilde{x}|x) dt
q σ i ( x ~ ) ≜ ∫ p d a t a ( x ) q σ i ( x ~ ∣ x ) d t
和之前一样,可以通过采样法得到x ~ \tilde{x} x ~
公式1.12
x ~ = x + σ i 2 ϵ , ϵ ∼ 0 , I \tilde{x} = x + \sigma^2_i \epsilon , \quad \epsilon \sim \mathcal{0,\textit{I}}
x ~ = x + σ i 2 ϵ , ϵ ∼ 0 , I
相比于 DDPM ,这里没有定义一个 α \alpha α σ i 2 \sigma^2_i σ i 2
σ i 2 \sigma^2_i σ i 2 σ 0 2 \sigma^2_0 σ 0 2 σ L 2 \sigma^2_L σ L 2
直观地,高噪声有助于分数函数的估计 ,但也会导致样本损坏 ;而较低的噪声给出了干净的样本,但使得分函数更难估计。
接下来利用上述的分层分数匹配(Sliced score matching)或者降噪分数匹配(Denoising score matching)
学习一个分数估计模型,它能在不同噪声强度下估计出扰动加噪后数据的分数 。在这里分层分数匹配和降噪分数匹配两种方法都可以使用,没有特别的限制。
条件高斯分布q σ i ( x ~ ∣ x ) q_{\sigma_i}(\tilde{x}| x) q σ i ( x ~ ∣ x )
公式1.13
∇ x ~ log q σ i ( x ~ ∣ x ) = − x ~ − x σ i 2 \nabla_{\tilde{x}} \log q_{\sigma_i}(\tilde{x}| x)=
- \frac{\tilde{x}-x}{\sigma_i^2}
∇ x ~ log q σ i ( x ~ ∣ x ) = − σ i 2 x ~ − x
按照降噪分数匹配的方法,单一噪声强度的目标函数为
公式1.14
ℓ ( θ ; σ i ) ≜ 1 2 E p d a t a ( x ) E x ~ ∼ x , σ i 2 I [ ∥ s θ ( x ~ , σ i ) − ∇ x ~ log q σ ( x ~ ∣ x ) ∥ 2 2 ] = 1 2 E p d a t a ( x ) E x ~ ∼ x , σ i 2 I [ ∥ s θ ( x ~ , σ i ) + x ~ − x σ i 2 ∥ 2 2 ] \ell(\theta;\sigma_i) \\ \triangleq \frac{1}{2} \mathbb{E}_{p_{data}(x)}
\mathbb{E}_{\tilde{x} \sim \mathcal{x,\sigma_i^2 \textit{I}}}
\left [ \left\lVert s_{\theta}(\tilde{x},\sigma_i) -\nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}|x) \right\rVert^2_2 \right ]
\\ = \frac{1}{2} \mathbb{E}_{p_{data}(x)}
\mathbb{E}_{\tilde{x} \sim \mathcal{x,\sigma_i^2 \textit{I}}}
\left [ \left\lVert s_{\theta}(\tilde{x},\sigma_i) + \frac{\tilde{x}-x}{\sigma_i^2} \right\rVert^2_2 \right ]
ℓ ( θ ; σ i ) ≜ 2 1 E p d a t a ( x ) E x ~ ∼ x , σ i 2 I [ ∥ s θ ( x ~ , σ i ) − ∇ x ~ log q σ ( x ~ ∣ x ) ∥ 2 2 ] = 2 1 E p d a t a ( x ) E x ~ ∼ x , σ i 2 I [ ∥ ∥ ∥ ∥ ∥ s θ ( x ~ , σ i ) + σ i 2 x ~ − x ∥ ∥ ∥ ∥ ∥ 2 2 ]
s θ ( x ~ , σ i ) s_{\theta}(\tilde{x},\sigma_i) s θ ( x ~ , σ i ) x ~ \tilde{x} x ~ σ i \sigma_i σ i
公式1.15
L ( θ ; { σ i } i = 1 L ) ≜ 1 L ∑ i = 1 L λ ( σ i ) ℓ ( θ ; σ i ) \mathcal{L}(\theta;\{\sigma_i\}_{i=1}^L ) \triangleq \frac{1}{L} \sum_{i=1}^L \lambda(\sigma_i) \ell(\theta;\sigma_i)
L ( θ ; { σ i } i = 1 L ) ≜ L 1 i = 1 ∑ L λ ( σ i ) ℓ ( θ ; σ i )
这就是最终的目标函数了,其中 λ ( σ i ) \lambda(\sigma_i) λ ( σ i ) σ i \sigma_i σ i σ i \sigma_i σ i
目标函数中包含一个方差项 σ i 2 \sigma_i^2 σ i 2 σ i \sigma_i σ i σ i \sigma_i σ i 公式1.14的数量级不同,所以这里可以令 λ ( σ i ) = σ i 2 \lambda(\sigma_i)=\sigma_i^2 λ ( σ i ) = σ i 2
公式1.16
λ ( σ i ) ℓ ( θ ; σ i ) = σ i 2 1 2 E p d a t a ( x ) E x ~ ∼ x , σ i 2 I [ ∥ s θ ( x ~ , σ i ) + x ~ − x σ i 2 ∥ 2 2 ] = 1 2 E p d a t a ( x ) E x ~ ∼ x , σ i 2 I [ ∥ σ i s θ ( x ~ , σ i ) + x ~ − x σ i ∥ 2 2 ] \lambda(\sigma_i) \ell(\theta;\sigma_i) \\= \sigma_i^2 \frac{1}{2} \mathbb{E}_{p_{data}(x)}
\mathbb{E}_{\tilde{x} \sim \mathcal{x,\sigma_i^2 \textit{I}}}
\left [ \left\lVert s_{\theta}(\tilde{x},\sigma_i) + \frac{\tilde{x}-x}{\sigma_i^2} \right\rVert^2_2 \right ]
\\= \frac{1}{2} \mathbb{E}_{p_{data}(x)}
\mathbb{E}_{\tilde{x} \sim \mathcal{x,\sigma_i^2 \textit{I}}}
\left [ \left\lVert \sigma_i s_{\theta}(\tilde{x},\sigma_i) + \frac{\tilde{x}-x}{\sigma_i} \right\rVert^2_2 \right ]
λ ( σ i ) ℓ ( θ ; σ i ) = σ i 2 2 1 E p d a t a ( x ) E x ~ ∼ x , σ i 2 I [ ∥ ∥ ∥ ∥ ∥ s θ ( x ~ , σ i ) + σ i 2 x ~ − x ∥ ∥ ∥ ∥ ∥ 2 2 ] = 2 1 E p d a t a ( x ) E x ~ ∼ x , σ i 2 I [ ∥ ∥ ∥ ∥ ∥ σ i s θ ( x ~ , σ i ) + σ i x ~ − x ∥ ∥ ∥ ∥ ∥ 2 2 ]
此时有 x ~ − x σ i ∼ N ( 0 , I ) \frac{\tilde{x}-x}{\sigma_i} \sim \mathcal{N}(0,\textit{I}) σ i x ~ − x ∼ N ( 0 , I )
基于分数的改进采样算法
通过上一步的加噪分数匹配方法,训练出了一个神经网络模型,这个神经网络模型可以预测不同等级的加噪数据的分数 s θ ( x ~ , σ i ) s_{\theta}(\tilde{x},\sigma_i) s θ ( x ~ , σ i ) p d a t a ( x ) p_{data}(x) p d a t a ( x )
基于分数的采样方法其实有多种,作者这里采样的郎之万动力采样法 (Langevin dynamic sample),然而前文我们讨论过,郎之万动力采样法存在着不足,对于那些存在低密度区域分割成多个高密度区域的复杂分布,需要较多的采样步骤才能得到相对可靠的采样结果,无法在一个可接受的步骤内得到较好的采样结果,针对这个问题,作者提出了一个改进的郎之万动力采样法,称为退火郎之万动力采样法
算法的过程其实不复杂,首先初始化超参数 { σ i } i = 1 L \{\sigma_i\}_{i=1}^L { σ i } i = 1 L x ~ 0 \tilde{x}_0 x ~ 0
接下来就是两层循环,外层循环是噪声等级的循环 ,从较大噪声等级的 σ 1 ≈ = 1 \sigma_1 \approx=1 σ 1 ≈ = 1 σ L ≈ 0 \sigma_L \approx 0 σ L ≈ 0 每个噪声等级下 的 q s i g m a i ( x ~ ) q_{sigma_i}(\tilde{x}) q s i g m a i ( x ~ ) 采样 。
这样一直到最后一步 i = L i=L i = L σ L ≈ 0 \sigma_L \approx 0 σ L ≈ 0 q s i g m a L ( x ~ ) ≈ p d a t a ( x ) q_{sigma_L}(\tilde{x}) \approx p_{data}(x) q s i g m a L ( x ~ ) ≈ p d a t a ( x ) 近似是原数据分布 p d a t a ( x ) p_{data}(x) p d a t a ( x )
因为是两层循环,内循环是原始的郎之万动力采样,外循环是一个噪声等级逐步降低 的过程,两层循环加起来构成了退火郎之万动力采样。
改进的分数生成模型
原始的分数模型,作者在 32 × 32 32 \times 32 3 2 × 3 2
作者进行了大量的分析和试验后,提出了了5项改进,这里不再赘述分析和试验过程的细节,只列出这5项改进内容,对细节感兴趣的同学可以阅读原论文 Yang Song and Stefano Ermon. Improved techniques for training score-based generative models. 2020。
初始噪声等级 σ 1 \sigma_1 σ 1 σ 1 \sigma_1 σ 1 σ 1 \sigma_1 σ 1
{ σ i } i = 1 L \{\sigma_i\}_{i=1}^L { σ i } i = 1 L γ \gamma γ γ = σ i − 1 / σ i \gamma=\sigma_{i-1}/\sigma_i γ = σ i − 1 / σ i γ \gamma γ Φ ( 2 D ( γ − 1 ) + 3 γ ) − Φ ( 2 D ( γ − 1 ) − 3 γ ) ≈ 0.5 \Phi(\sqrt{2 D}(\gamma-1)+3\gamma)-\Phi(\sqrt{2 D}(\gamma-1)-3\gamma)\approx 0.5 Φ ( 2 D ( γ − 1 ) + 3 γ ) − Φ ( 2 D ( γ − 1 ) − 3 γ ) ≈ 0 . 5 Φ \Phi Φ D D D x x x
神经网络模型由原来的的 s θ ( x ~ , σ i ) s_{\theta}(\tilde{x},\sigma_i) s θ ( x ~ , σ i ) s θ ( x ~ ) / σ i s_{\theta}(\tilde{x})/\sigma_i s θ ( x ~ ) / σ i σ i \sigma_i σ i
在计算预算允许的范围内选择 T T T ϵ \epsilon ϵ 1 1 1
公式1.17
s T 2 σ i 2 = ( 1 − ϵ σ L 2 ) 2 T ( γ 2 − 2 ϵ σ L 2 − σ L 2 ( 1 − ϵ σ L 2 ) 2 ) + 2 ϵ σ L 2 − σ L 2 ( 1 − ϵ σ L 2 ) 2 \frac{s^2_T}{\sigma_i^2} \\= \left( 1-\frac{\epsilon}{\sigma_L^2} \right)^{2T}
\left( \gamma^2-\frac{2\epsilon}{\sigma_L^2-\sigma_L^2 \left( 1-\frac{\epsilon}{\sigma_L^2} \right)^2 } \right)
+ \frac{2\epsilon}{\sigma_L^2-\sigma_L^2 \left( 1-\frac{\epsilon}{\sigma_L^2} \right)^2 }
σ i 2 s T 2 = ( 1 − σ L 2 ϵ ) 2 T ⎝ ⎜ ⎜ ⎛ γ 2 − σ L 2 − σ L 2 ( 1 − σ L 2 ϵ ) 2 2 ϵ ⎠ ⎟ ⎟ ⎞ + σ L 2 − σ L 2 ( 1 − σ L 2 ϵ ) 2 2 ϵ
训练模型时加入指数滑动平均(exponential moving average,EMA)技术,$\theta_{ema} \leftarrow m\theta_{ema} + (1 − m)\theta_t $ ,得到一份 EMA 的模型参数副本,其中 m = 0.999 m = 0.999 m = 0 . 9 9 9 θ e m a \theta_{ema} θ e m a θ e m a \theta_{ema} θ e m a
训练完成后输出保存的是两套模型参数,在推理时可以选择用原始模型参数还是使用 EMA 版本的参数。EMA 版本的参数理论上能缓解原始参数过拟合的情况,
经过这五项改进后模型在生成图像的多样性和质量上都得到大幅提升,可以生成较高质量的 256 × 256 256 \times 256 2 5 6 × 2 5 6